Table of Contents
Introduction: What is Kubernetes Architecture?
Kubernetes, an open-source container orchestration platform, has become the industry standard for managing and deploying containerized applications. It automates application deployment, scaling, and operations of containerized applications across clusters of hosts. At the core of Kubernetes lies its powerful architecture, which is designed to provide high availability, scalability, and resilience in large-scale production environments.
In this article, we will break down the key components of Kubernetes architecture, explore its inner workings, and showcase real-world use cases that demonstrate how this platform can be leveraged for enterprise-level application management.
The Components of Kubernetes Architecture
Understanding the structure of Kubernetes is essential to grasp how it functions. Kubernetes’ architecture consists of two primary layers:
- Master Node: The control plane, responsible for managing and controlling the Kubernetes cluster.
- Worker Nodes: The physical or virtual machines that run the applications and services.
Let’s explore each of these components in detail.
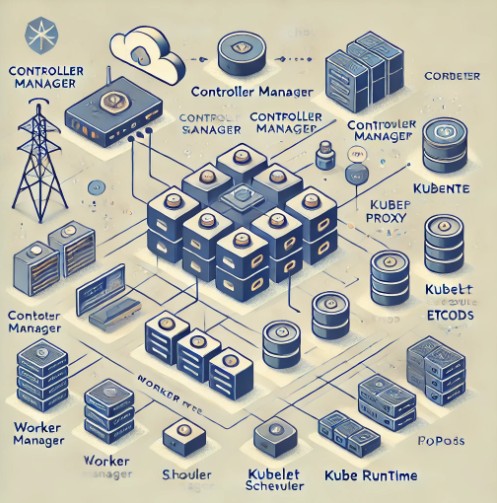
Master Node: The Brain Behind Kubernetes
The master node is the heart of the Kubernetes architecture. It runs the Kubernetes control plane and is responsible for making global decisions about the cluster (e.g., scheduling and scaling). The master node ensures that the cluster operates smoothly by managing critical tasks, such as maintaining the desired state of the applications, responding to failures, and ensuring scalability.
The master node consists of several key components:
- API Server: The API server serves as the entry point for all REST commands used to control the cluster. It is responsible for exposing Kubernetes’ functionality through a REST interface and acts as a gateway for communication between the components in the cluster.
- Controller Manager: The controller manager ensures that the current state of the cluster matches the desired state. It runs controllers such as the ReplicaSet Controller, Deployment Controller, and Node Controller.
- Scheduler: The scheduler is responsible for selecting which worker node should run a pod. It watches for newly created pods and assigns them to an appropriate node based on available resources and other factors such as affinity and taints.
- etcd: This is a highly available key-value store used to store all the cluster’s data, including the state of all objects like pods, deployments, and namespaces. It is crucial for ensuring that the cluster maintains its desired state even after a failure.
Worker Nodes: Where the Action Happens
Worker nodes are where the applications actually run in the Kubernetes environment. Each worker node runs the following components:
- Kubelet: This is an agent that runs on each worker node. It is responsible for ensuring that containers in its node are running as expected. The kubelet communicates with the API server to check if there are new pod configurations and applies the necessary changes.
- Kube Proxy: The kube proxy manages network communication and load balancing for the pods within the node. It ensures that traffic reaches the right pod based on its IP address or service name.
- Container Runtime: The container runtime is responsible for running containers within the worker node. Docker is the most common container runtime, although Kubernetes supports alternatives like containerd and CRI-O.
Pods: The Basic Unit of Deployment
A pod is the smallest deployable unit in Kubernetes. A pod can contain one or more containers that share the same network namespace, storage, and specification. Pods are scheduled and run on worker nodes and are ephemeral—when a pod fails or is deleted, Kubernetes automatically replaces it to ensure the application remains available.
Key Features of Pods:
- Shared Network: All containers within a pod share the same network and IP address, making inter-container communication simple.
- Ephemeral: Pods are designed to be ephemeral, meaning they are created, terminated, and replaced as needed. This feature aligns with Kubernetes’ approach to high availability and self-healing.
- Storage: Pods can also share storage volumes, which are used to persist data across restarts.
Services: Exposing Applications to the Network
In Kubernetes, a service is an abstraction that defines a set of pods and provides a stable endpoint for them. Services enable the communication between different parts of the application by providing a single DNS name or IP address for accessing a set of pods.
There are several types of services:
- ClusterIP: Exposes the service on an internal IP address within the cluster. This is the default service type.
- NodePort: Exposes the service on a static port on each node’s IP address, making the service accessible from outside the cluster.
- LoadBalancer: Uses an external load balancer to expose the service, often used in cloud environments.
- ExternalName: Maps a service to an external DNS name.
Volumes: Persistent Storage in Kubernetes
Kubernetes provides several types of volumes that allow applications to store and retrieve data. Volumes are abstracted from the underlying infrastructure and provide storage that persists beyond the lifecycle of individual pods. Some common volume types include:
- emptyDir: Provides temporary storage that is created when a pod is assigned to a node and is deleted when the pod is removed.
- PersistentVolume (PV) and PersistentVolumeClaim (PVC): Persistent volumes are abstracted storage resources, while claims allow users to request specific types of storage resources.
Namespaces: Organizing Resources
Namespaces in Kubernetes provide a way to organize cluster resources and create multiple virtual clusters within a single physical cluster. Namespaces are commonly used for multi-tenant environments or to separate different environments (e.g., development, testing, production) within the same Kubernetes cluster.
Real-World Example: Kubernetes Architecture in Action
Scenario 1: Deploying a Simple Web Application
Imagine you have a simple web application that needs to be deployed on Kubernetes. In a typical Kubernetes architecture setup, you would create a deployment that manages the pods containing your application, expose the application using a service, and ensure persistence with a volume.
Steps:
- Create a Pod Deployment: Define the pod with your web application container.
- Expose the Application: Use a service of type
LoadBalancerto expose the application to the internet. - Scale the Application: Use the Kubernetes
kubectl scalecommand to horizontally scale the application by adding more pod replicas.
Scenario 2: Scaling and Managing Resources
In a high-traffic application, you may need to scale up the number of pods running your service. Kubernetes makes it easy to increase or decrease the number of replicas automatically, based on resource utilization or custom metrics.
Scenario 3: Self-Healing and Recovery
One of the most impressive features of Kubernetes is its self-healing capabilities. For example, if one of your pods fails or crashes, Kubernetes will automatically replace it with a new pod, ensuring the application remains available without manual intervention.
Frequently Asked Questions (FAQ)
1. What is the role of the API Server in Kubernetes architecture?
The API Server serves as the central control point for all communication between the components in the Kubernetes cluster. It provides the interface for users and components to interact with the cluster’s resources.
2. How does Kubernetes handle application scaling?
Kubernetes can automatically scale applications using a Horizontal Pod Autoscaler, which adjusts the number of pod replicas based on CPU usage, memory usage, or custom metrics.
3. What is the difference between a pod and a container?
A pod is a wrapper around one or more containers, ensuring they run together on the same host and share network resources. Containers are the actual applications running within the pod.
4. How does Kubernetes ensure high availability?
Kubernetes provides high availability through features such as replication (running multiple copies of a pod) and self-healing (automatically replacing failed pods).
5. Can Kubernetes run on any cloud platform?
Yes, Kubernetes is cloud-agnostic and can run on any cloud platform such as AWS, Azure, or Google Cloud, as well as on-premises infrastructure.
Conclusion: The Power of Kubernetes Architecture
Kubernetes architecture is designed to provide high availability, scalability, and resilience, making it an ideal choice for managing containerized applications in production. By understanding the key components, including the master and worker nodes, pods, services, and persistent storage, you can better leverage Kubernetes to meet the needs of your organization’s workloads.
Whether you are just starting with Kubernetes or looking to optimize your existing setup, understanding its architecture is crucial for building robust, scalable applications. Thank you for reading the DevopsRoles page!
For more information, visit the official Kubernetes documentation here.

