Table of Contents
- 1 Introduction
- 2 Prerequisites
- 3 Load data from S3 to Redshift into Redshift example with AWS CLI
- 3.1 Install PSQL on MacOS
- 3.2 Creating a data warehouse with Amazon Redshift using AWS CLI
- 3.3 Connect to the Redshift cluster using PSQL
- 3.4 Create Redshift cluster tables using PSQL
- 3.5 Redshift default role setting uses AWS Console manage
- 3.6 Loading sample data from S3 to Redshift with PSQL
- 3.7 Delete the sample cluster using AWS CLI
- 4 Conclusion
Introduction
This tutorial shows you how to create a Redshift cluster resource, connect to Amazon Redshift, load sample data from S3 to Redshift into Redshift, and run queries with data usage command line tools.
You can use SQL Workbench or Amazon Redshift Query Editor v2.0 (web-based analyst workbench). In this tutorial, we choose to load sample data from an Amazon S3 bucket to Amazon Redshift using the PLSQL command-line tool.
psql is a terminal-based front-end to PostgreSQL. It enables you to type in queries interactively, issue them to PostgreSQL, and see the query results. Alternatively, input can be from a file or command line arguments. In addition, psql provides several meta-commands and various shell-like features to facilitate writing scripts and automating a wide variety of tasks.
Prerequisites
Before starting, you should have the following prerequisites configured
- An AWS account
- AWS CLI on your computer
Load data from S3 to Redshift into Redshift example with AWS CLI
- Install PSQL on MacOS
- Creating a data warehouse with Amazon Redshift using AWS CLI
- Connect to the Redshift cluster using PSQL
- Create Redshift cluster tables using PSQL
- Redshift default role setting uses AWS Console manage
- Loading sample data from S3 to Redshift with PSQL
- Delete the sample cluster using AWS CLI
Install PSQL on MacOS
We can choose a version from PostgresSQL page or execute the following command on MacOS
brew install postgresql
Creating a data warehouse with Amazon Redshift using AWS CLI
Before you begin, If you have not installed the AWS CLI, see Setting up the Amazon Redshift CLI. This tutorial uses the us-east-1 region.
Now we’re ready to launch a cluster by using the AWS CLI.
The create-cluster the command has a large number of parameters. For this tutorial, you will use the parameter values that are described in the following table. Before you create a cluster in a production environment, we recommend that you review all the required and optional parameters so that your cluster configuration matches your requirements. For more information, see create-cluster
| Parameter name | Parameter value for this exercise |
| cluster-identifier | examplecluster |
| master-username | awsuser |
| master-user-password | Awsuser123 |
| node-type | dc2.large |
| cluster-type | single-node |
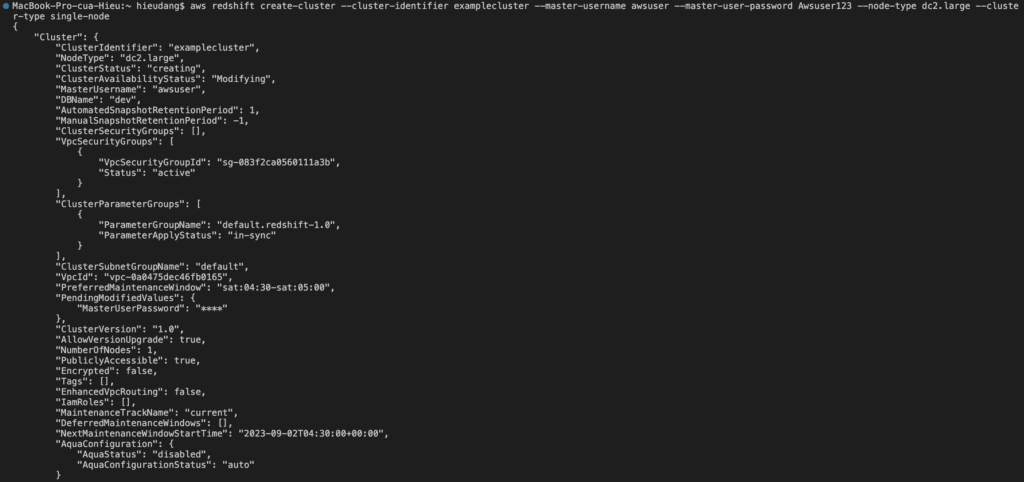
Run the following command to create a cluster.
aws redshift create-cluster --cluster-identifier examplecluster --master-username awsuser --master-user-password Awsuser123 --node-type dc2.large --cluster-type single-nodeThis command returns the following result.
The cluster creation process will take several minutes to complete. To check the status, enter the following command.
aws redshift describe-clusters --cluster-identifier examplecluster | grep ClusterStatus
When the ClusterStatus field changes from creating to available, the cluster is ready for use.
Connect to the Redshift cluster using PSQL
Run the following command to connect to the Redshift cluster.
psql -h examplecluster.ccfmryooawwy.us-east-1.redshift.amazonaws.com -U awsuser -d dev -p 5439
You must explicitly grant inbound access to your client to connect to the cluster. When you created a cluster in the previous step, because you did not specify a security group, you associated the default cluster security group with the cluster.
The default cluster security group contains no rules to authorize any inbound traffic to the cluster. To access the new cluster, you must add rules for inbound traffic, which are called ingress rules, to the cluster security group. If you are accessing your cluster from the Internet, you will need to authorize a Classless Inter-Domain Routing IP (CIDR/IP) address range.
#get VpcSecurityGroupId
aws redshift describe-clusters --cluster-identifier examplecluster | grep VpcSecurityGroupId
Run the following command to enable your computer to connect to your Redshift cluster. Then login into your cluster using psql.
#allow connect to cluster from my computer
aws ec2 authorize-security-group-ingress --group-id sg-083f2ca0560111a3b --protocol tcp --port 5439 --cidr 111.111.111.111/32This command returns the following result.
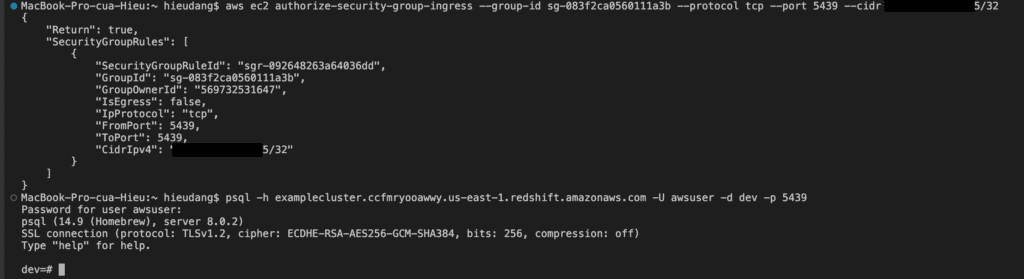
Now test the connection by querying the system table
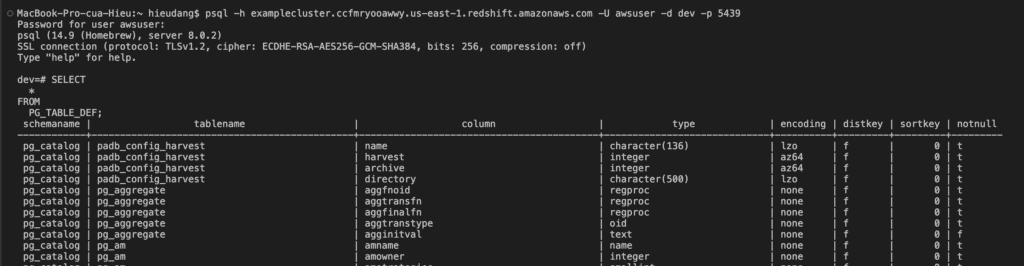
Create Redshift cluster tables using PSQL
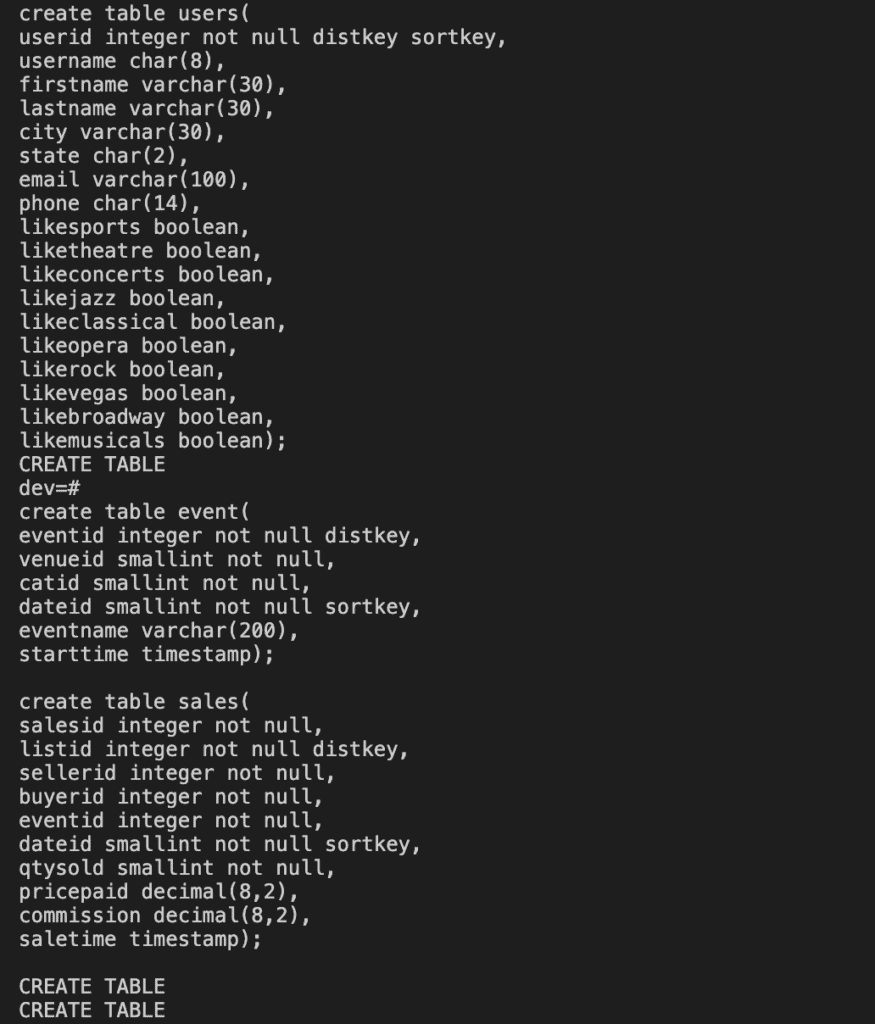
In this tutorial, I use sample data from AWS. Run the following command to create Redshift tables.
create table users(
userid integer not null distkey sortkey,
username char(8),
firstname varchar(30),
lastname varchar(30),
city varchar(30),
state char(2),
email varchar(100),
phone char(14),
likesports boolean,
liketheatre boolean,
likeconcerts boolean,
likejazz boolean,
likeclassical boolean,
likeopera boolean,
likerock boolean,
likevegas boolean,
likebroadway boolean,
likemusicals boolean);
create table event(
eventid integer not null distkey,
venueid smallint not null,
catid smallint not null,
dateid smallint not null sortkey,
eventname varchar(200),
starttime timestamp);
create table sales(
salesid integer not null,
listid integer not null distkey,
sellerid integer not null,
buyerid integer not null,
eventid integer not null,
dateid smallint not null sortkey,
qtysold smallint not null,
pricepaid decimal(8,2),
commission decimal(8,2),
saletime timestamp);This command returns the following result.
Test by querying the public.sales table as follows
select * from public.sales;
Redshift default role setting uses AWS Console manage
Before you can load data from Amazon S3, you must first create an IAM role with the necessary permissions and attach it to your cluster. To do this refer to AWS document

Loading sample data from S3 to Redshift with PSQL
Use the COPY command to load large datasets from Amazon S3 into Amazon Redshift. For more information about COPY syntax, see COPY in the Amazon Redshift Database Developer Guide.
Run the following SQL commands in PSQL to load data from S3 to Redshift
COPY users
FROM 's3://redshift-downloads/tickit/allusers_pipe.txt'
DELIMITER '|'
TIMEFORMAT 'YYYY-MM-DD HH:MI:SS'
IGNOREHEADER 1
REGION 'us-east-1'
IAM_ROLE default;
COPY event
FROM 's3://redshift-downloads/tickit/allevents_pipe.txt'
DELIMITER '|'
TIMEFORMAT 'YYYY-MM-DD HH:MI:SS'
IGNOREHEADER 1
REGION 'us-east-1'
IAM_ROLE default;
COPY sales
FROM 's3://redshift-downloads/tickit/sales_tab.txt'
DELIMITER '\t'
TIMEFORMAT 'MM/DD/YYYY HH:MI:SS'
IGNOREHEADER 1
REGION 'us-east-1'
IAM_ROLE default;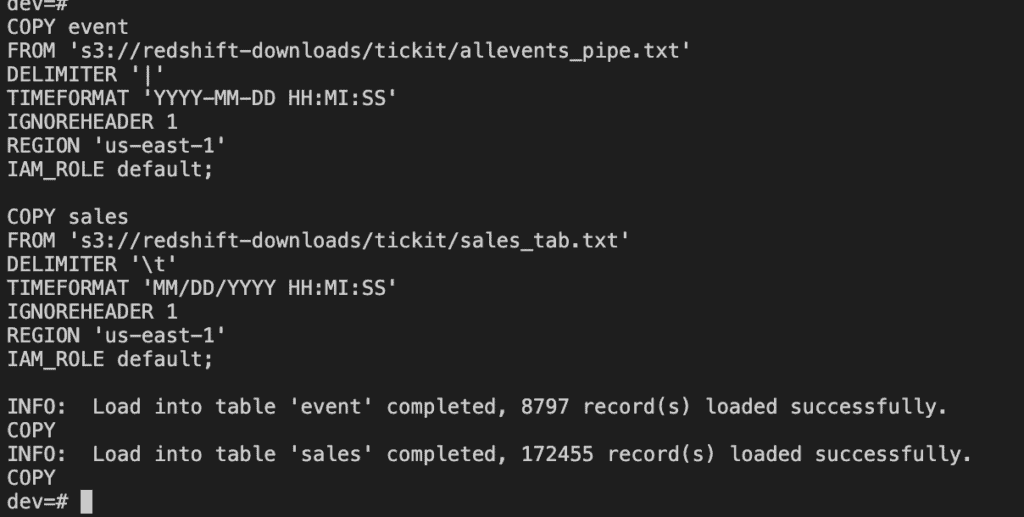
After loading data, try some example queries.
\timing
SELECT firstname, lastname, total_quantity
FROM (SELECT buyerid, sum(qtysold) total_quantity
FROM sales
GROUP BY buyerid
ORDER BY total_quantity desc limit 10) Q, users
WHERE Q.buyerid = userid
ORDER BY Q.total_quantity desc;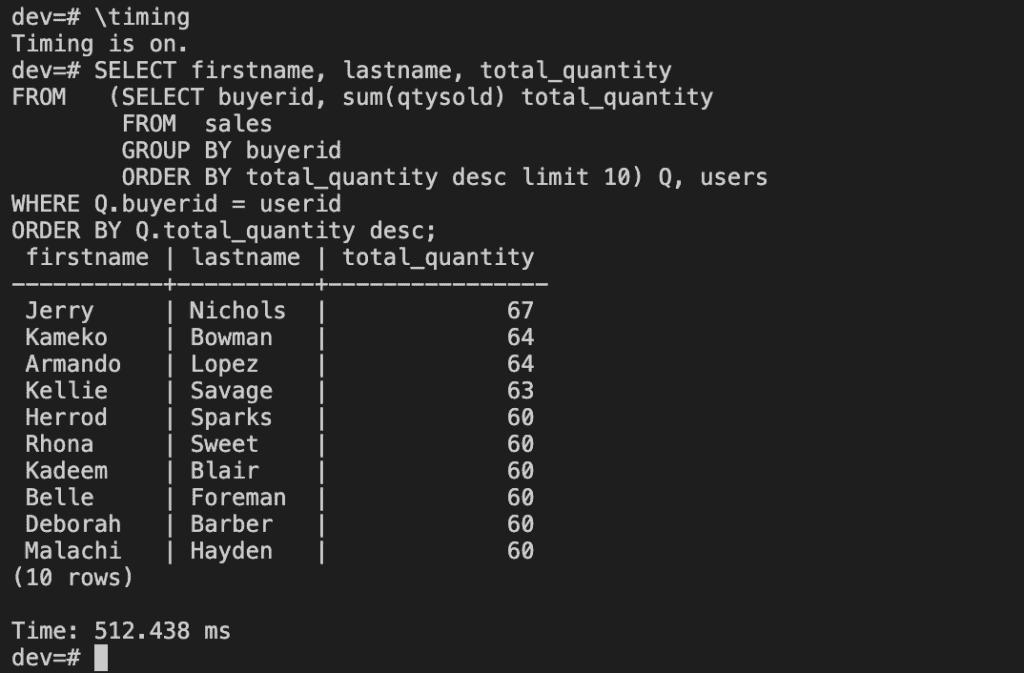
Now that you’ve loaded data into Redshift.
Delete the sample cluster using AWS CLI
When you delete a cluster, you must decide whether to create a final snapshot. Because this is an exercise and your test cluster should not have any important data in it, you can skip the final snapshot.
To delete your cluster, enter the following command.
aws redshift delete-cluster –cluster-identifier examplecluster –skip-final-cluster-snapshot

Congratulations! You successfully launched, authorized access to, connected to, and terminated a cluster.
Conclusion
These steps provide an example of loading data from S3 to Redshift into Redshift with the PSQL tool. The specific configuration details may vary depending on your environment and setup. It’s recommended to consult the relevant documentation from AWS for detailed instructions on setting up. I hope will this be helpful. Thank you for reading the DevopsRoles page!
Refer
https://docs.aws.amazon.com/redshift/latest/gsg/new-user-serverless.html


